Kanalcodierung/Schranken für die Blockfehlerwahrscheinlichkeit: Unterschied zwischen den Versionen
| Zeile 86: | Zeile 86: | ||
== Union Bound der Blockfehlerwahrscheinlichkeit == | == Union Bound der Blockfehlerwahrscheinlichkeit == | ||
<br> | <br> | ||
| − | Wir betrachten wie im | + | Wir betrachten wie im Beispiel 1 zum Distanzspektrum] den $(5, \hspace{0.02cm} 2)$–Blockcode $\mathcal{C} = (\underline{x}_0, \underline{x}_1, \underline{x}_2, \underline{x}_3)$ und setzen voraus, dass das Codewort $\underline{x}_0$ gesendet wurde. Die Grafik verdeutlicht den Sachverhalt). |
| − | [[Datei:P ID2366 KC T 1 6 S2b v2.png|Zur Herleitung der Union Bound |class=fit]] | + | [[Datei:P ID2366 KC T 1 6 S2b v2.png|center|frame|Zur Herleitung der Union Bound |class=fit]] |
| − | Im fehlerfreien Fall würde dann der Codewortschätzer | + | Im fehlerfreien Fall würde dann der Codewortschätzer $\underline{z} = \underline{x}_0$ liefern. Andernfalls käme es zu einem Blockfehler (das heißt $\underline{z} \ne \underline{x}_0$ und dementsprechend $\underline{v} \ne \underline{u}_0$ mit der Wahrscheinlichkeit |
| − | :<math>{\rm Pr(Blockfehler)} = {\rm Pr}\left ([\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}1}] \hspace{0.05cm}\cup\hspace{0.05cm}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}2}] \hspace{0.05cm}\cup\hspace{0.05cm}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}3}] \right ) | + | ::<math>{\rm Pr(Blockfehler)} = {\rm Pr}\left ([\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}1}] \hspace{0.05cm}\cup\hspace{0.05cm}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}2}] \hspace{0.05cm}\cup\hspace{0.05cm}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}3}] \right ) |
\hspace{0.05cm}.</math> | \hspace{0.05cm}.</math> | ||
| − | Das Ereignis „Verfälschung von | + | Das Ereignis „Verfälschung von $\underline{x}_0$ nach $\underline{x}_1$” tritt für ein gegebenes Empfangswort $\underline{y}$ entsprechend der [[Kanalcodierung/Kanalmodelle_und_Entscheiderstrukturen#Definitionen_der_verschiedenen_Optimalempf.C3.A4nger|Maximum–Likelihood–Entscheidungsregel]] (block–wise ML) genau dann ein, wenn für die bedingte Wahrscheinlichkeitsdichtefunktion gilt: |
| − | :<math>[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}1}] \hspace{0.3cm} \Longleftrightarrow \hspace{0.3cm} | + | ::<math>[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}1}] \hspace{0.3cm} \Longleftrightarrow \hspace{0.3cm} |
f(\underline{x}_{\hspace{0.02cm}0}\hspace{0.02cm} | \hspace{0.05cm}\underline{y}) < f(\underline{x}_{\hspace{0.02cm}1}\hspace{0.02cm} | \hspace{0.05cm}\underline{y}) | f(\underline{x}_{\hspace{0.02cm}0}\hspace{0.02cm} | \hspace{0.05cm}\underline{y}) < f(\underline{x}_{\hspace{0.02cm}1}\hspace{0.02cm} | \hspace{0.05cm}\underline{y}) | ||
\hspace{0.05cm}.</math> | \hspace{0.05cm}.</math> | ||
| − | Da [ | + | Da $[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}1}] $, $[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}2}] $, $[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}3}] $nicht notwendigerweise <i>disjunkte Ereignisse</i> sind (die sich somit gegenseitig ausschließen würden), ist die [[Stochastische_Signaltheorie/Mengentheoretische_Grundlagen#Vereinigungsmenge| Wahrscheinlichkeit der Vereinigungsmenge]] kleiner oder gleich der Summe der Einzelwahrscheinlichkeiten: |
:<math>{\rm Pr(Blockfehler)} \le {\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}1}] \hspace{0.05cm}+\hspace{0.05cm}{\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}2}] \hspace{0.05cm}+ \hspace{0.05cm}{\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}3}] | :<math>{\rm Pr(Blockfehler)} \le {\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}1}] \hspace{0.05cm}+\hspace{0.05cm}{\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}2}] \hspace{0.05cm}+ \hspace{0.05cm}{\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}3}] | ||
\hspace{0.05cm}.</math> | \hspace{0.05cm}.</math> | ||
| − | Man nennt diese obere Schranke für die (Block–)Fehlerwahrscheinlichkeit die Union Bound. Diese wurde bereits im [ | + | Man nennt diese obere Schranke für die (Block–)Fehlerwahrscheinlichkeit die '''Union Bound'''. Diese wurde bereits im Kapitel [[Digitalsignal%C3%BCbertragung/Approximation_der_Fehlerwahrscheinlichkeit#Union_Bound_-_Obere_Schranke_f.C3.BCr_die_Fehlerwahrscheinlichkeit|Approximation_der_Fehlerwahrscheinlichkeit]] des Buches „Digitalsignalübertragung” verwendet.<br> |
| − | Verallgemeinern und formalisieren wir diese Ergebnisse | + | Verallgemeinern und formalisieren wir diese Ergebnisse unter der Voraussetzung, dass sowohl $\underline{x}$ als auch $\underline{x}'$ zum Code $\mathcal{C}$ gehören. Dann gelten folgende Berechnungsvorschriften:<br> |
| − | + | {{BlaueBox|TEXT= | |
| − | + | $\text{Definitionen:}$ | |
| + | *'''Blockfehlerwahrscheinlichkeit''': | ||
| − | :<math>{\rm Pr(Blockfehler)} = {\rm Pr} \left ( \bigcup_{\underline{x}' \ne \underline{x}} \hspace{0.15cm} [\underline{x} \mapsto \underline{x}'] \right )\hspace{0.05cm},</math> | + | ::<math>{\rm Pr(Blockfehler)} = {\rm Pr} \left ( \bigcup_{\underline{x}' \ne \underline{x} } \hspace{0.15cm} [\underline{x} \mapsto \underline{x}'] \right )\hspace{0.05cm},</math> |
| − | Obere Schranke nach der | + | *Obere Schranke nach der '''Union Bound''': |
| − | :<math>{\rm Pr(Union \hspace{0.15cm}Bound)} \le \sum_{\underline{x}' \ne \underline{x}} \hspace{0.15cm} {\rm Pr}[\underline{x} \mapsto \underline{x}'] \hspace{0.05cm},</math> | + | ::<math>{\rm Pr(Union \hspace{0.15cm}Bound)} \le \sum_{\underline{x}' \ne \underline{x} } \hspace{0.15cm} {\rm Pr}[\underline{x} \mapsto \underline{x}'] \hspace{0.05cm},</math> |
| − | + | * '''Paarweise Fehlerwahrscheinlichkeit''' (nach dem MAP– bzw. ML–Kriterium): | |
| − | :<math>{\rm Pr}\hspace{0.02cm}[\underline{x} \mapsto \underline{x}'] = {\rm Pr} \left [ | + | ::<math>{\rm Pr}\hspace{0.02cm}[\underline{x} \mapsto \underline{x}'] = {\rm Pr} \left [ |
| − | f(\underline{x}\hspace{0.05cm} | + | f(\underline{x}\hspace{0.05cm}\vert \hspace{0.05cm}\underline{y}) \le f(\underline{x}'\hspace{0.05cm} \vert \hspace{0.05cm}\underline{y}) \right ] |
| − | \hspace{0.05cm}.</math> | + | \hspace{0.05cm}.</math>}} |
Auf den nächsten Seiten werden diese Ergebnisse auf verschiedene Kanäle angewendet.<br> | Auf den nächsten Seiten werden diese Ergebnisse auf verschiedene Kanäle angewendet.<br> | ||
| Zeile 131: | Zeile 132: | ||
Wir betrachten weiterhin den [http://www.lntwww.de/Kanalcodierung/Schranken_f%C3%BCr_die_Blockfehlerwahrscheinlichkeit#Distanzspektrum_eines_linearen_Codes_.281.29 beispielhaften (5, 2)–Code:]<br> | Wir betrachten weiterhin den [http://www.lntwww.de/Kanalcodierung/Schranken_f%C3%BCr_die_Blockfehlerwahrscheinlichkeit#Distanzspektrum_eines_linearen_Codes_.281.29 beispielhaften (5, 2)–Code:]<br> | ||
| − | :[[Datei:P ID2406 KC T 1 6 S2 v2.png|BSC–Modell und ML–Detektion|class=fit]] | + | :[[Datei:P ID2406 KC T 1 6 S2 v2.png|center|frame|BSC–Modell und ML–Detektion|class=fit]] |
Für den digitalen Kanal verwenden wir das [http://www.lntwww.de/Kanalcodierung/Klassifizierung_von_Signalen#Binary_Symmetric_Channel_.E2.80.93_BSC BSC–Modell] (<i>Binary Symmetric Channel</i>): | Für den digitalen Kanal verwenden wir das [http://www.lntwww.de/Kanalcodierung/Klassifizierung_von_Signalen#Binary_Symmetric_Channel_.E2.80.93_BSC BSC–Modell] (<i>Binary Symmetric Channel</i>): | ||
| Zeile 155: | Zeile 156: | ||
In der Tabelle sind die Ergebnisse für verschiedene Werte des BSC–Parameters <i>ε</i> zusammengefasst:<br> | In der Tabelle sind die Ergebnisse für verschiedene Werte des BSC–Parameters <i>ε</i> zusammengefasst:<br> | ||
| − | [[Datei:P ID2367 KC T 1 6 S3 neu.png|Zahlenmäßige Union Bound für den (5, 2)–Code|class=fit]] | + | [[Datei:P ID2367 KC T 1 6 S3 neu.png|center|frame|Zahlenmäßige Union Bound für den (5, 2)–Code|class=fit]] |
Zu erwähnen ist, dass die völlig unterschiedlich zu berechnenden Wahrscheinlichkeiten Pr(<i><u>x</u></i><sub>0</sub> → <i><u>x</u></i><sub>1</sub>) und Pr(<i><u>x</u></i><sub>0</sub> → <i><u>x</u></i><sub>3</sub>) genau das gleiche Ergebnis liefern.<br> | Zu erwähnen ist, dass die völlig unterschiedlich zu berechnenden Wahrscheinlichkeiten Pr(<i><u>x</u></i><sub>0</sub> → <i><u>x</u></i><sub>1</sub>) und Pr(<i><u>x</u></i><sub>0</sub> → <i><u>x</u></i><sub>3</sub>) genau das gleiche Ergebnis liefern.<br> | ||
| Zeile 219: | Zeile 220: | ||
\hspace{0.05cm}.</math> | \hspace{0.05cm}.</math> | ||
| − | [[Datei:P ID2370 KC T 1 6 S4.png|Vergleich von Union Bound und Bhattacharyya–Schranke beim BSC–Modell|class=fit]] | + | [[Datei:P ID2370 KC T 1 6 S4.png|center|frame|Vergleich von Union Bound und Bhattacharyya–Schranke beim BSC–Modell|class=fit]] |
Basierend auf diesem Beispiel für den einfachen (5, 2)–Code, der allerdings wenig praxisrelevant ist, sowie dem Beispiel auf der nächsten Seite für den (7, 4, 3)–Hamming–Code kann man zusammenfassen: | Basierend auf diesem Beispiel für den einfachen (5, 2)–Code, der allerdings wenig praxisrelevant ist, sowie dem Beispiel auf der nächsten Seite für den (7, 4, 3)–Hamming–Code kann man zusammenfassen: | ||
| Zeile 268: | Zeile 269: | ||
\hspace{0.05cm}.</math> | \hspace{0.05cm}.</math> | ||
| − | == Aufgaben == | + | == Aufgaben zum Kapitel == |
<br> | <br> | ||
[[Aufgaben:1.14 Bhattacharyya–Schranke für BEC|A1.14 Bhattacharyya–Schranke für BEC]] | [[Aufgaben:1.14 Bhattacharyya–Schranke für BEC|A1.14 Bhattacharyya–Schranke für BEC]] | ||
Version vom 15. November 2017, 15:09 Uhr
Inhaltsverzeichnis
Distanzspektrum eines linearen Codes
Wir gehen weiterhin von einem linearen und binären $(n, \hspace{0.05cm} k)$–Blockcode $\mathcal{C}$ aus. Ein wesentliches Ziel des Codedesigns ist es, die Blockfehlerwahrscheinlichkeit ${\rm Pr}(\underline{u} \ne \underline{v}) = {\rm Pr}(\underline{z} \ne \underline{x})$ möglichst gering zu halten. Dies erreicht man unter anderem dadurch, dass
- die minimale Distanz $d_{\rm min}$ zwischen zwei Codeworten $\underline{x}$ und $\underline{x}'$ möglichst groß ist, so dass man bis zu $t = ⌊(d_{\rm min}-1)/2⌋$ Bitfehler richtig korrigieren kann;
- gleichzeitig die minimale Distanz $d_{\rm min}$ ⇒ worst–case möglichst selten auftritt, wenn man alle zulässigen Codeworte berücksichtigt.
$\text{Definition:}$ Wir benennen die Anzahl der Codeworte $\underline{x}' \in \mathcal{C}$ mit der Hamming–Distanz $i$ vom betrachteten Codewort $\underline{x}$ des gleichen Codes $\mathcal{C}$ mit $W_i(\underline{x})$, wobei gilt:
- \[W_i(\underline{x}) = \left \vert \hspace{0.05cm} \left \{ \underline{x} \hspace{0.05cm}, \underline{x}{\hspace{0.03cm}' \in \hspace{0.05cm} \mathcal{C} } \hspace{0.1cm}\vert\hspace{0.1cm} d_{\rm H}(\underline{x} \hspace{0.05cm}, \hspace{0.1cm}\underline{x}' ) = i \right \} \hspace{0.05cm} \right \vert\hspace{0.05cm}.\]
- Die Betragsstriche kennzeichnen hierbei die Anzahl der Codeworte $\underline{x}'$, die die Bedingung $d_{\rm H}(\underline{x} \hspace{0.05cm}, \hspace{0.1cm}\underline{x}' ) = i $ erfüllen.
- Man bezeichnet diesen Wert auch als Vielfachheit (englisch: Multiplicity).

$\text{Beispiel 1:}$ Wir betrachten den $(5, \, 2)$–Blockcode $\mathcal{C}$ mit der Generatormatrix
\[{ \boldsymbol{\rm G} } = \begin{pmatrix} 1 &0 &1 &1 &0 \\ 0 &1 &0 &1 &1 \end{pmatrix} \hspace{0.05cm}.\]
Die Tabelle zeigt die Hamming–Distanzen zwischen allen Codeworten $\underline{x}_i$ zu den Bezugsworten $\underline{x}_0$, ... , $\underline{x}_3$.
Man erkennt, dass unabhängig vom Bezugswort $\underline{x}_i$ gilt:
- \[W_0 = 1 \hspace{0.05cm}, \hspace{0.5cm}W_1 = W_2 = 0 \hspace{0.05cm},\]
- \[ W_3 = 2 \hspace{0.05cm},\hspace{0.5cm} W_4 = 1\]
- \[ \Rightarrow\hspace{0.3cm} d_{\rm min} = 3\hspace{0.05cm}.\]
Nicht nur in diesem Beispiel, sondern bei jedem linearen Code ergeben sich für jedes Codewort die gleichen Vielfachheiten $W_i$. Da zudem das Nullwort $\underline{0} = (0, 0,\text{ ...} \hspace{0.05cm}, 0)$ Bestandteil eines jeden linearen Binärcodes ist, lässt sich die obige Definition auch wie folgt formulieren:
$\text{Definition:}$ Das Distanzspektrum eines linearen binären $(n, \hspace{0.03cm} k)$–Blockcodes ist die Menge $\{W_i \}$ mit $i = 0, 1,$ ... , $n$. Hierbei gibt $W_i$ die Anzahl der Codeworte $\underline{x} \in \mathcal{C}$ mit Hamming–Gewicht $w_{\rm H}(\underline{x}) = i$ an.
Oft beschreibt man die Menge $\hspace{0.05cm}\{W_i \}\hspace{0.05cm}$ auch als Polynom mit einer Pseudovariablen $X$:
- \[\left \{ \hspace{0.05cm} W_i \hspace{0.05cm} \right \} \hspace{0.3cm} \Leftrightarrow \hspace{0.3cm} W(X) = \sum_{i=0 }^{n} W_i \cdot Xi^{i} = W_0 + W_1 \cdot X + W_2 \cdot X^{2} + ... \hspace{0.05cm} + W_n \cdot X^{n}\hspace{0.05cm}.\]
Man bezeichnet $W(X)$ auch als Gewichtsfunktion (englisch: Weight Enumerator Function, WEF).
Beispielsweise lautet die Gewichtsfunktion des $(5, \hspace{0.02cm} 2)$–Codes $\mathcal{C} = \left \{ \hspace{0.05cm}(0, 0, 0, 0, 0) \hspace{0.05cm},\hspace{0.15cm} (0, 1, 0, 1, 1) \hspace{0.05cm},\hspace{0.15cm}(1, 0, 1, 1, 0) \hspace{0.05cm},\hspace{0.15cm}(1, 1, 1, 0, 1) \hspace{0.05cm} \right \}$ von Beispiel 1:
- \[W(X) = 1 + 2 \cdot X^{3} + X^{4}\hspace{0.05cm}.\]
Wie aus der Tabelle seiner Codeworte hervorgeht, erhält man für den $(7, \hspace{0.02cm}4, \hspace{0.02cm}3)$–Hamming–Code:
- \[W(X) = 1 + 7 \cdot X^{3} + 7 \cdot X^{4} + X^{7}\hspace{0.05cm}.\]
Die Überführung des Distanzspektrums $\hspace{0.01cm}\{W_i \}\hspace{0.01cm}$ in die Gewichtsfunktion $W(X)$ bietet zudem bei manchen Aufgabenstellungen große numerische Vorteile. Ist beispielsweise die Weight Enumerator Function $W(X)$ eines $(n, \hspace{0.03cm} k)$–Blockcodes $\mathcal{C}$ bekannt, so gilt für den hierzu dualen $(n, \hspace{0.03cm} n-k)$–Code $\mathcal{C}_{\rm Dual}$:
- \[W_{\rm Dual}(X) = \frac{(1+X)^n}{2^k} \cdot W \left ( \frac{1-X}{1+X} \right )\hspace{0.05cm}.\]
$\text{Beispiel 2:}$ Gesucht ist die Gewichtsfunktion $W(X)$ des Single Parity–check Codes mit $n = 6$, $k = 5$ ⇒ SPC (6, 5). Man erhält diese durch Vergleich aller $2^5 = 32$ Codeworte mit dem Nullwort:
- \[W_{\rm SPC\hspace{0.03cm}(6,\hspace{0.08cm}5)}(X) = 1 + 15 \cdot X^{2} + 15 \cdot X^{4} + X^{6}\hspace{0.05cm}.\]
Unter Berücksichtigung obiger Gleichung kommt man sehr viel schneller zum gleichen Ergebnis:
- Der zu SPC (6, 5) duale Code ist der Repetition Code RC (6, 1) mit nur zwei Codeworten $(0, 0, 0, 0, 0, 0)$ und $(1, 1, 1, 1, 1, 1)$:
- \[W_{\rm RC\hspace{0.03cm}(6,\hspace{0.08cm}1)}(X) = 1 + X^{6}\hspace{0.05cm}.\]
- Daraus folgt für die Gewichtsfunktion des SPC (6, 5) nach obiger Gleichung mit $k = 1$:
- \[W_{\rm SPC\hspace{0.03cm}(6,\hspace{0.08cm}5)}(X) = \frac{(1+X)^6}{2^1} \cdot W \left [1 + \left ( (1-X)/(1+X)\right )^6 \right ] = 1/2 \cdot \left [( 1+X) ^6 + ( 1-X) ^6 \right ] = 1 + 15 \cdot X^{2} + 15 \cdot X^{4} + X^{6}\hspace{0.05cm}.\]
Union Bound der Blockfehlerwahrscheinlichkeit
Wir betrachten wie im Beispiel 1 zum Distanzspektrum] den $(5, \hspace{0.02cm} 2)$–Blockcode $\mathcal{C} = (\underline{x}_0, \underline{x}_1, \underline{x}_2, \underline{x}_3)$ und setzen voraus, dass das Codewort $\underline{x}_0$ gesendet wurde. Die Grafik verdeutlicht den Sachverhalt).

Im fehlerfreien Fall würde dann der Codewortschätzer $\underline{z} = \underline{x}_0$ liefern. Andernfalls käme es zu einem Blockfehler (das heißt $\underline{z} \ne \underline{x}_0$ und dementsprechend $\underline{v} \ne \underline{u}_0$ mit der Wahrscheinlichkeit
- \[{\rm Pr(Blockfehler)} = {\rm Pr}\left ([\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}1}] \hspace{0.05cm}\cup\hspace{0.05cm}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}2}] \hspace{0.05cm}\cup\hspace{0.05cm}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}3}] \right ) \hspace{0.05cm}.\]
Das Ereignis „Verfälschung von $\underline{x}_0$ nach $\underline{x}_1$” tritt für ein gegebenes Empfangswort $\underline{y}$ entsprechend der Maximum–Likelihood–Entscheidungsregel (block–wise ML) genau dann ein, wenn für die bedingte Wahrscheinlichkeitsdichtefunktion gilt:
- \[[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}1}] \hspace{0.3cm} \Longleftrightarrow \hspace{0.3cm} f(\underline{x}_{\hspace{0.02cm}0}\hspace{0.02cm} | \hspace{0.05cm}\underline{y}) < f(\underline{x}_{\hspace{0.02cm}1}\hspace{0.02cm} | \hspace{0.05cm}\underline{y}) \hspace{0.05cm}.\]
Da $[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}1}] $, $[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}2}] $, $[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}3}] $nicht notwendigerweise disjunkte Ereignisse sind (die sich somit gegenseitig ausschließen würden), ist die Wahrscheinlichkeit der Vereinigungsmenge kleiner oder gleich der Summe der Einzelwahrscheinlichkeiten:
\[{\rm Pr(Blockfehler)} \le {\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}1}] \hspace{0.05cm}+\hspace{0.05cm}{\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}2}] \hspace{0.05cm}+ \hspace{0.05cm}{\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}3}] \hspace{0.05cm}.\]
Man nennt diese obere Schranke für die (Block–)Fehlerwahrscheinlichkeit die Union Bound. Diese wurde bereits im Kapitel Approximation_der_Fehlerwahrscheinlichkeit des Buches „Digitalsignalübertragung” verwendet.
Verallgemeinern und formalisieren wir diese Ergebnisse unter der Voraussetzung, dass sowohl $\underline{x}$ als auch $\underline{x}'$ zum Code $\mathcal{C}$ gehören. Dann gelten folgende Berechnungsvorschriften:
$\text{Definitionen:}$
- Blockfehlerwahrscheinlichkeit:
- \[{\rm Pr(Blockfehler)} = {\rm Pr} \left ( \bigcup_{\underline{x}' \ne \underline{x} } \hspace{0.15cm} [\underline{x} \mapsto \underline{x}'] \right )\hspace{0.05cm},\]
- Obere Schranke nach der Union Bound:
- \[{\rm Pr(Union \hspace{0.15cm}Bound)} \le \sum_{\underline{x}' \ne \underline{x} } \hspace{0.15cm} {\rm Pr}[\underline{x} \mapsto \underline{x}'] \hspace{0.05cm},\]
- Paarweise Fehlerwahrscheinlichkeit (nach dem MAP– bzw. ML–Kriterium):
- \[{\rm Pr}\hspace{0.02cm}[\underline{x} \mapsto \underline{x}'] = {\rm Pr} \left [ f(\underline{x}\hspace{0.05cm}\vert \hspace{0.05cm}\underline{y}) \le f(\underline{x}'\hspace{0.05cm} \vert \hspace{0.05cm}\underline{y}) \right ] \hspace{0.05cm}.\]
Auf den nächsten Seiten werden diese Ergebnisse auf verschiedene Kanäle angewendet.
Union Bound für das BSC–Modell
Wir betrachten weiterhin den beispielhaften (5, 2)–Code:
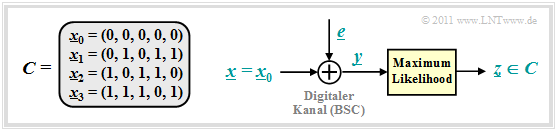 BSC–Modell und ML–Detektion
BSC–Modell und ML–Detektion

Für den digitalen Kanal verwenden wir das BSC–Modell (Binary Symmetric Channel):
\[{\rm Pr}(y = 1 \hspace{0.05cm} | \hspace{0.05cm}x = 0 ) \hspace{-0.15cm} = {\rm Pr}(y = 0 \hspace{0.05cm} | \hspace{0.05cm}x = 1 ) = {\rm Pr}(e = 1) = \varepsilon \hspace{0.05cm},\] \[{\rm Pr}(y = 0 \hspace{0.05cm} | \hspace{0.05cm}x = 0 ) \hspace{-0.15cm} = {\rm Pr}(y = 1 \hspace{0.05cm} | \hspace{0.05cm}x = 1 ) = {\rm Pr}(e = 0) = 1 -\varepsilon \hspace{0.05cm}.\]
Die beiden Codeworte x0 = (0, 0, 0, 0, 0) und x1 = (0, 1, 0, 1, 1) unterscheiden sich in genau d = 3 Bitpositionen, wobei d die Hamming–Distanz zwischen x0 und x1 angibt. Ein falsches Decodierergebnis [x0 → x1] erhält man immer dann, wenn mindestens zwei der drei Bit an den Bitpositionen 2, 4 und 5 verfälscht werden. Die Bitpositionen 1 und 3 spielen hier dagegen keine Rolle, da diese für x0 und x1 gleich sind. Da der betrachtete Code t = ⌊(d–1)/2⌋ = 1 Fehler korrigieren kann, gilt:
\[{\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}1}] \hspace{-0.1cm} = \hspace{-0.1cm} \sum_{i=t+1 }^{d} {d \choose i} \cdot \varepsilon^{i} \cdot (1 - \varepsilon)^{d-i} = {3 \choose 2} \cdot \varepsilon^{2} \cdot (1 - \varepsilon) + {3 \choose 3} \cdot \varepsilon^{3} =\] \[\hspace{2.5cm} = \hspace{-0.1cm} 3 \cdot \varepsilon^2 \cdot (1 - \varepsilon) + \varepsilon^3 = {\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}2}]\hspace{0.05cm}.\]
Die Codeworte x0 und x3 unterscheiden sich in vier Bitpositionen. Zu einer falschen Decodierung des Blocks kommt es deshalb mit Sicherheit, wenn vier oder drei Bit verfälscht werden. Eine Verfälschung von zwei Bit hat mit 50–prozentiger Wahrscheinlichkeit ebenfalls einen Blockfehler zur Folge, wenn man hierfür eine Zufallsentscheidung voraussetzt:
\[{\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}3}] = \varepsilon^4 + 4 \cdot \varepsilon^3 \cdot (1 - \varepsilon) + {1}/{2} \cdot 6 \cdot \varepsilon^2 \cdot (1 - \varepsilon)^2 \hspace{0.05cm}.\]
Daraus ergibt sich für die „Union Bound”:
\[{\rm Pr(Union \hspace{0.15cm}Bound)} = {\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \hspace{-0.02cm}\mapsto \hspace{-0.02cm}\underline{x}_{\hspace{0.02cm}1}] +{\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \hspace{-0.02cm}\mapsto \hspace{-0.02cm} \underline{x}_{\hspace{0.02cm}2}] +{\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \hspace{-0.02cm}\mapsto \hspace{-0.02cm} \underline{x}_{\hspace{0.02cm}3}] \ge {\rm Pr(Blockfehler)} .\]
In der Tabelle sind die Ergebnisse für verschiedene Werte des BSC–Parameters ε zusammengefasst:

Zu erwähnen ist, dass die völlig unterschiedlich zu berechnenden Wahrscheinlichkeiten Pr(x0 → x1) und Pr(x0 → x3) genau das gleiche Ergebnis liefern.
Die obere Schranke nach Bhattacharyya (1)
Eine weitere obere Schranke für die Blockfehlerwahrscheinlichkeit wurde von Bhattacharyya angegeben:
\[{\rm Pr(Blockfehler)} \le W(X = \beta) -1 = {\rm Pr(Bhattacharyya)} \hspace{0.05cm}.\]
Hierzu ist anzumerken:
- W(X) ist die zu Beginn dieses Kapitels 1.6 definierte Gewichtsfunktion, die den verwendeten Kanalcode charakterisiert.
- Der Bhattacharyya–Parameter β kennzeichnet den digitalen Kanal. Beispielsweise gilt:
- \[\beta = \left\{ \begin{array}{c} \lambda \\ \sqrt{4 \cdot \varepsilon \cdot (1- \varepsilon)}\\ {\rm exp}[- R \cdot E_{\rm B}/N_0] \end{array} \right.\quad \begin{array}{*{1}c} {\rm f\ddot{u}r\hspace{0.15cm} das \hspace{0.15cm}BEC-Modell},\\ {\rm f\ddot{u}r\hspace{0.15cm} das \hspace{0.15cm}BSC-Modell}, \\ {\rm f\ddot{u}r\hspace{0.15cm} das \hspace{0.15cm}AWGN-Modell}. \end{array}\]
- Die Bhattacharyya–Schranke liegt stets (und meist deutlich) oberhalb der Kurve für die „Union Bound”. Mit dem Ziel, eine für alle Kanäle einheitliche Schranke zu finden, müssen hier sehr viel gröbere Abschätzungen vorgenommen werden als für die Herleitung der Union Bound.
Bhattacharyya–Schranke für das BSC–Modell
Für die paarweise Verfälschungswahrscheinlichkeit des BSC–Modells wurde vorne hergeleitet:
\[{\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}1}] = \sum_{i= \left\lfloor (d-1)/2 \right\rfloor}^{d} {d \choose i} \cdot \varepsilon^{i} \cdot (1 - \varepsilon)^{d-i} = \sum_{i= \left\lceil d/2 \right\rceil }^{d} {d \choose i} \cdot \varepsilon^{i} \cdot (1 - \varepsilon)^{d-i}\hspace{0.05cm}.\]
Hierbei kennzeichnet ε = Pr(y = 1| x = 0) = Pr(y = 0| x = 1) < 0.5 das BSC–Modell und d = dH(x0, x1) gibt die Hamming–Distanz der betrachteten Codeworte an.
Um zur Bhattacharyya–Schranke zu kommen, müssen folgende Abschätzungen getroffen werden:
- Für alle i < d gilt εi · (1 – ε)d – i ≤ [ε · (1 – ε)]d/2:
- \[{\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}1}] \le [\varepsilon \cdot (1 - \varepsilon)]^{d/2} \cdot \sum_{i= \left\lceil d/2 \right\rceil }^{d} {d \choose i} \hspace{0.05cm}.\]
- Änderung bezüglich der unteren Grenze der Laufvariablen i:
- \[\sum_{i= \left\lceil d/2 \right\rceil }^{d} {d \choose i} \hspace{0.15cm} < \hspace{0.15cm} \sum_{i= 0 }^{d} {d \choose i} = 2^d\hspace{0.05cm}, \hspace{0.2cm}\beta = 2 \cdot \sqrt{\varepsilon \cdot (1 - \varepsilon)} \hspace{0.3cm} \Rightarrow \hspace{0.3cm} {\rm Pr}[\underline{x}_{\hspace{0.02cm}0} \mapsto \underline{x}_{\hspace{0.02cm}1}] = \beta^{d} \hspace{0.05cm}.\]
- Umsortierung gemäß den Hamming–Gewichten Wi (Hamming–Distanz d = i kommt Wi mal vor):
- \[{\rm Pr(Blockfehler)} \hspace{0.1cm} \le \hspace{0.1cm} \sum_{i= 1 }^{n} W_i \cdot \beta^{i} = 1 + W_1 \cdot \beta + W_2 \cdot \beta^2 + ... \hspace{0.05cm}+ W_n \cdot \beta^n \hspace{0.05cm}.\]
- Mit der Gewichtsfunktion W(X) = 1 + W1 · X + W2 · X 2 + ... + Wn · X n:
- \[{\rm Pr(Blockfehler)} \le W(X = \beta) -1= {\rm Pr(Bhattacharyya)} \hspace{0.05cm}.\]
Die obere Schranke nach Bhattacharyya (2)
In der Tabelle ist die Bhattacharyya–Schranke für verschiedene BSC–Parameter ε abgegeben, gültig für den beispielhaften (5, 2)–Code. Für diesen gilt:
\[W_0 = 1 \hspace{0.05cm},\hspace{0.2cm} W_1 = W_2 = 0 \hspace{0.05cm},\hspace{0.2cm}W_3 = 2 \hspace{0.05cm},\hspace{0.2cm} W_4 = 1 \hspace{0.3cm} \Rightarrow\hspace{0.3cm} W(X) = 1 + 2 \cdot X^3 + X^4\]
\[\Rightarrow \hspace{0.3cm} {\rm Pr(Blockfehler)} \le W(\beta) -1 = 2 \cdot \beta^3 + \beta^4 = {\rm Pr(Bhattacharyya)} \hspace{0.05cm}.\]

Basierend auf diesem Beispiel für den einfachen (5, 2)–Code, der allerdings wenig praxisrelevant ist, sowie dem Beispiel auf der nächsten Seite für den (7, 4, 3)–Hamming–Code kann man zusammenfassen:
- Die Blockfehlerwahrscheinlichkeit eines Codiersystems ist oft analytisch nicht angebbar und muss per Simulation ermittelt werden. Gleiches gilt für die Bitfehlerwahrscheinlichkeit.
- Die Union Bound liefert eine obere Schranke für die Blockfehlerwahrscheinlichkeit. Bei vielen Anwendungen (insbesondere bei kurzen Codes) liegt sie nur geringfügig über dieser.
- Die Bhattacharyya–Schranke liegt beim BEC–Kanal etwa um den Faktor 2 oberhalb der Union Bound – siehe Aufgabe A1.14. Beim BSC– und beim AWGN–Kanal ist der Abstand zwischen beiden Schranken deutlich größer. Der Faktor 10 (oder mehr) ist keine Seltenheit.
- Die Bhattacharyya–Schranke W(β) – 1 wirkt auf den ersten Blick sehr einfach. Es sind einige Vereinfachungsschritte erforderlich, um auf diese Form zu kommen. Trotzdem benötigt man auch hier Kenntnis über die genaue Gewichtsfunktion W(ξ) des Codes.
- Bei Kenntnis des Übertragungskanals (BEC, BSC, AWGN oder Abwandlungen hiervon) und dessen Parameter spricht vom Aufwand her nichts dagegen, die Union Bound als obere Schranke für die Blockfehlerwahrscheinlichkeit zu verwenden.
Schranken für den (7, 4, 3)–Hamming–Code beim AWGN–Kanal
Abschließend betrachten wir die Blockfehlerwahrscheinlichkeit und deren Schranken (Union Bound und Bhattacharyya–Schranke) für die folgende Konfiguration:
- AWGN–Kanal, gekennzeichnet durch den Quotienten EB/N0,
- Hamming–Code (7, 4) ⇒ R = 4/7, W(X) – 1 = 7 · X3 + 7 · X4 + X7,
- Soft–Decision nach dem ML–Kriterium.
Die Ergebnisse sind in der folgenden Grafik zusammengefasst. Im Gegensatz zur Grafik im Kapitel 1.5 ist hier die Blockfehlerrate angegeben und nicht die Bitfehlerrate. Näherungsweise ist Letztere um den Faktor dmin/k kleiner, falls wie hier dmin < k ist. Im vorliegenden Beispiel gilt dmin/k = 0.75.

Die folgenden Zahlenwerte gelten für 10 · lg EB/N0 = 8 dB ⇒ EB/N0 = 6.31 (blaue Markierungen):
- Die grünen Kreuze markieren die Union Bound. Nach dieser gilt:
- \[{\rm Pr(Blockfehler)} \hspace{-0.15cm} \le \hspace{-0.15cm} \sum_{i= d_{\rm min} }^{n} W_i \cdot {\rm Q} \left ( \sqrt{i \cdot {2R \cdot E_{\rm B}}/{N_0}} \right ) =\]
- \[\hspace{3cm} = \hspace{-0.15cm} 7 \cdot {\rm Q} (4.65) + 7 \cdot {\rm Q} (5.37) + {\rm Q} (7.10) = \]
- \[\hspace{3cm} \approx \hspace{-0.15cm} 7 \cdot 1.66 \cdot 10^{-6} + 7 \cdot 3.93 \cdot 10^{-8}+ 10^{-9} = 1.2 \cdot 10^{-5} \hspace{0.05cm}.\]
- Die Zahlenwerte machen deutlich, dass die Union Bound durch den ersten Term bestimmt wird:
- \[{\rm Pr(Union\hspace{0.15cm} Bound)} \approx W_{d_{\rm min}} \cdot {\rm Q} \left ( \sqrt{d_{\rm min} \cdot {2R \cdot E_{\rm B}}/{N_0}} \right ) = 1.16 \cdot 10^{-5} \hspace{0.05cm}.\]
- Allerdings ist diese sog. Truncated Union Bound nicht mehr bei allen Anwendungen eine echte Schranke für die Blockfehlerwahrscheinlichkeit, sondern ist eher als Näherung zu verstehen.
- Die Bhattacharyya–Schranke ist in der Grafik durch rote Punkte markiert. Diese Schranke liegt aufgrund der stark vereinfachten Chernoff–Rubin Bound Q(x) ≤ exp(– x2/2) deutlich über der Union Bound. Für 10 · lg EB/N0 = 8 dB erhält man mit β = exp[–R · EB/N0] ≈ 0.027:
- \[{\rm Pr(Bhattacharyya)} = W(\beta) -1 = 7 \cdot \beta^3 + 7 \cdot \beta^4 + \beta^7 \approx 1.44 \cdot 10^{-4} \hspace{0.05cm}.\]
Aufgaben zum Kapitel
A1.14 Bhattacharyya–Schranke für BEC
Zusatzaufgaben:1.16 Schranken für Q(x)