Informationstheorie/Nachrichtenquellen mit Gedächtnis: Unterschied zwischen den Versionen
| Zeile 226: | Zeile 226: | ||
==Binärquellen mit Markoveigenschaften == | ==Binärquellen mit Markoveigenschaften == | ||
<br> | <br> | ||
| − | [[Datei:Inf_T_1_2_S5_vers2.png|right|frame|Markovprozesse mit | + | [[Datei:Inf_T_1_2_S5_vers2.png|right|frame|Markovprozesse mit $M = 2$ Zuständen]] |
Folgen mit statistischen Bindungen zwischen den Folgenelementen (Symbolen) werden oft durch [[Stochastische_Signaltheorie/Markovketten|Markovprozesse]] modelliert, wobei wir uns hier auf Markovprozesse erster Ordnung beschränken. Zunächst betrachten wir einen binären Markovprozess $(M = 2)$ mit den Zuständen (Symbolen) $\rm A$ und $\rm B$. | Folgen mit statistischen Bindungen zwischen den Folgenelementen (Symbolen) werden oft durch [[Stochastische_Signaltheorie/Markovketten|Markovprozesse]] modelliert, wobei wir uns hier auf Markovprozesse erster Ordnung beschränken. Zunächst betrachten wir einen binären Markovprozess $(M = 2)$ mit den Zuständen (Symbolen) $\rm A$ und $\rm B$. | ||
| + | |||
Rechts sehen Sie das Übergangsdiagramm für einen binären Markovprozess erster Ordnung. Von den vier angegebenen Übertragungswahrscheinlichkeiten sind allerdings nur zwei frei wählbar, zum Beispiel | Rechts sehen Sie das Übergangsdiagramm für einen binären Markovprozess erster Ordnung. Von den vier angegebenen Übertragungswahrscheinlichkeiten sind allerdings nur zwei frei wählbar, zum Beispiel | ||
* $p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}B}} = \rm Pr(A\hspace{0.01cm}|\hspace{0.01cm}B)$ ⇒ bedingte Wahrscheinlichkeit, dass $\rm A$ auf $\rm B$ folgt. | * $p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}B}} = \rm Pr(A\hspace{0.01cm}|\hspace{0.01cm}B)$ ⇒ bedingte Wahrscheinlichkeit, dass $\rm A$ auf $\rm B$ folgt. | ||
| Zeile 234: | Zeile 235: | ||
| − | Für die beiden weiteren Übergangswahrscheinlichkeiten gilt dann $p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}A} = 1- p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}A} | + | Für die beiden weiteren Übergangswahrscheinlichkeiten gilt dann $p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}A} = 1- p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}A}$ und $p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}B} = 1- p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}B} |
| − | |||
\hspace{0.05cm}.$ | \hspace{0.05cm}.$ | ||
| Zeile 245: | Zeile 245: | ||
Diese Gleichungen erlauben erste informationstheoretische Aussagen über Markovprozesse: | Diese Gleichungen erlauben erste informationstheoretische Aussagen über Markovprozesse: | ||
| − | * Für $p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}B}} = p_{\rm {B\hspace{0.01cm}|\hspace{0.01cm}A}}$ sind die Symbole gleichwahrscheinlich ⇒ $p_{\text{A}} = p_{\text{B}}= 0.5$. Die erste Entropienäherung liefert $H_1 = H_0 = 1 \hspace{0.05cm} \rm bit/Symbol$, und zwar unabhängig von den tatsächlichen Werten der (bedingten) Übergangswahrscheinlichkeiten $p_{\text{A|B}}$ bzw. $p_{\text{B|A}}$. | + | * Für $p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}B}} = p_{\rm {B\hspace{0.01cm}|\hspace{0.01cm}A}}$ sind die Symbole gleichwahrscheinlich ⇒ $p_{\text{A}} = p_{\text{B}}= 0.5$. Die erste Entropienäherung liefert $H_1 = H_0 = 1 \hspace{0.05cm} \rm bit/Symbol$, und zwar unabhängig von den tatsächlichen Werten der (bedingten) Übergangswahrscheinlichkeiten $p_{\text{A|B}}$ bzw. $p_{\text{B|A}}$. |
| − | *Die Quellenentropie $H$ als der Grenzwert der [[Informationstheorie/Nachrichtenquellen_mit_Gedächtnis#Verallgemeinerung_auf_k.E2.80.93Tupel_und_Grenz.C3.BCbergang|Entropienäherung $k$–ter Ordnung]] $H_k$ | + | *Die Quellenentropie $H$ als der Grenzwert (für $k \to \infty$) der [[Informationstheorie/Nachrichtenquellen_mit_Gedächtnis#Verallgemeinerung_auf_k.E2.80.93Tupel_und_Grenz.C3.BCbergang|Entropienäherung $k$–ter Ordnung]] ⇒ $H_k$ hängt aber sehr wohl von den tatsächlichen Werten von $p_{\text{A|B}}$ und $p_{\text{B|A}}$ ab und nicht nur von ihrem Quotienten. Dies zeigt das folgende Beispiel. |
{{GraueBox|TEXT= | {{GraueBox|TEXT= | ||
$\text{Beispiel 6:}$ | $\text{Beispiel 6:}$ | ||
| − | Wir betrachten drei binäre symmetrische Markovquellen, die sich durch die Zahlenwerte der symmetrischen Übergangswahrscheinlichkeiten $p_{\rm {A\hspace{0.01cm}\vert\hspace{0.01cm}B} } = p_{\rm {B\hspace{0.01cm}\vert\hspace{0.01cm}A} }$ unterscheiden. Für die Symbolwahrscheinlichkeiten gilt somit | + | Wir betrachten drei binäre symmetrische Markovquellen, die sich durch die Zahlenwerte der symmetrischen Übergangswahrscheinlichkeiten $p_{\rm {A\hspace{0.01cm}\vert\hspace{0.01cm}B} } = p_{\rm {B\hspace{0.01cm}\vert\hspace{0.01cm}A} }$ unterscheiden. Für die Symbolwahrscheinlichkeiten gilt somit $p_{\rm A} = p_{\rm B}= 0.5,$ und die anderen Übergangswahrscheinlichkeiten haben dann die Werte |
| − | p_{\rm {B\hspace{0.01cm}\vert\hspace{0.01cm}B} }.$ | + | |
| + | [[Datei:P_ID2242__Inf_T_1_2_S5b_neu.png|right|frame|Drei Beispiele binärer Markovquellen]] | ||
| + | :$$p_{\rm {A\hspace{0.01cm}\vert\hspace{0.01cm}A} } = 1 - p_{\rm {B\hspace{0.01cm}\vert\hspace{0.01cm}A} } = | ||
| + | p_{\rm {B\hspace{0.01cm}\vert\hspace{0.01cm}B} }.$$ | ||
| − | + | *Die mittlere (blaue) Symbolfolge mit $p_{\rm {A\hspace{0.01cm}\vert\hspace{0.01cm}B} } = p_{\rm {B\hspace{0.01cm}\vert\hspace{0.01cm}A} } = 0.5$ besitzt die Entropie $H ≈ 1 \hspace{0.05cm} \rm bit/Symbol$. Das heißt: In diesem Sonderfall gibt es keine statistischen Bindungen innerhalb der Folge. | |
| − | |||
*Die linke (rote) Folge mit $p_{\rm {A\hspace{0.01cm}\vert\hspace{0.01cm}B} } = p_{\rm {B\hspace{0.01cm}\vert\hspace{0.01cm}A} } = 0.25$ weist weniger Wechsel zwischen $\rm A$ und $\rm B$ auf. Aufgrund von statistischen Abhängigkeiten zwischen benachbarten Symbolen ist nun $H ≈ 0.72 \hspace{0.05cm} \rm bit/Symbol$ kleiner. | *Die linke (rote) Folge mit $p_{\rm {A\hspace{0.01cm}\vert\hspace{0.01cm}B} } = p_{\rm {B\hspace{0.01cm}\vert\hspace{0.01cm}A} } = 0.25$ weist weniger Wechsel zwischen $\rm A$ und $\rm B$ auf. Aufgrund von statistischen Abhängigkeiten zwischen benachbarten Symbolen ist nun $H ≈ 0.72 \hspace{0.05cm} \rm bit/Symbol$ kleiner. | ||
| + | |||
*Die rechte (grüne) Symbolfolge mit $p_{\rm {A\hspace{0.01cm}\vert\hspace{0.01cm}B} } = p_{\rm {B\hspace{0.01cm}\vert\hspace{0.01cm}A} } = 0.8$ hat die genau gleiche Entropie $H ≈ 0.72 \hspace{0.05cm} \rm bit/Symbol$ wie die rote Folge. Hier erkennt man viele Bereiche mit sich stets abwechselnden Symbolen (... $\rm ABABAB$ ... ).}} | *Die rechte (grüne) Symbolfolge mit $p_{\rm {A\hspace{0.01cm}\vert\hspace{0.01cm}B} } = p_{\rm {B\hspace{0.01cm}\vert\hspace{0.01cm}A} } = 0.8$ hat die genau gleiche Entropie $H ≈ 0.72 \hspace{0.05cm} \rm bit/Symbol$ wie die rote Folge. Hier erkennt man viele Bereiche mit sich stets abwechselnden Symbolen (... $\rm ABABAB$ ... ).}} | ||
| Zeile 263: | Zeile 266: | ||
Zu diesem Beispiel ist noch anzumerken: | Zu diesem Beispiel ist noch anzumerken: | ||
*Hätte man nicht die Markoveigenschaften der roten und der grünen Folge ausgenutzt, so hätte man das Ergebnis $H ≈ 0.72 \hspace{0.05cm} \rm bit/Symbol$ erst nach langwierigen Berechnungen erhalten. | *Hätte man nicht die Markoveigenschaften der roten und der grünen Folge ausgenutzt, so hätte man das Ergebnis $H ≈ 0.72 \hspace{0.05cm} \rm bit/Symbol$ erst nach langwierigen Berechnungen erhalten. | ||
| − | *Auf den nächsten Seiten wird gezeigt, dass bei einer Quelle mit Markoveigenschaften | + | *Auf den nächsten Seiten wird gezeigt, dass bei einer Quelle mit Markoveigenschaften der Endwert $H$ allein aus den Entropienäherungen $H_1$ und $H_2$ ermittelt werden kann. Ebenso lassen sich aus $H_1$ und $H_2$ alle Entropienäherungen $H_k$ für $k$–Tupel in einfacher Weise berechnen ⇒ $H_3$, $H_4$, $H_5$, ... , $H_{100}$, ... |
| − | |||
==Vereinfachte Entropieberechnung bei Markovquellen == | ==Vereinfachte Entropieberechnung bei Markovquellen == | ||
<br> | <br> | ||
| − | [[Datei:Inf_T_1_2_S5_vers2.png|right|frame|Markovprozesse mit | + | [[Datei:Inf_T_1_2_S5_vers2.png|right|frame|Markovprozesse mit $M = 2$ Zuständen]] |
Wir gehen weiterhin von der symmetrischen binären Markovquelle erster Ordnung aus. Wie auf der vorherigen Seite verwenden wir folgende Nomenklatur für | Wir gehen weiterhin von der symmetrischen binären Markovquelle erster Ordnung aus. Wie auf der vorherigen Seite verwenden wir folgende Nomenklatur für | ||
| − | *die Übergangswahrscheinlichkeiten $p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}B}}$, ... | + | *die Übergangswahrscheinlichkeiten $p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}B}}$, $p_{\rm {B\hspace{0.01cm}|\hspace{0.01cm}A}}$, $p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}A}}= 1- p_{\rm {B\hspace{0.01cm}|\hspace{0.01cm}A}}$, $p_{\rm {B\hspace{0.01cm}|\hspace{0.01cm}B}} = 1 - p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}B}}$, |
*die ergodischen Wahrscheinlichkeiten $p_{\text{A}}$ und $p_{\text{B}}$, | *die ergodischen Wahrscheinlichkeiten $p_{\text{A}}$ und $p_{\text{B}}$, | ||
*die Verbundwahrscheinlichkeiten, zum Beispiel $p_{\text{AB}} = p_{\text{A}} · p_{\rm {B\hspace{0.01cm}|\hspace{0.01cm}A}}$. | *die Verbundwahrscheinlichkeiten, zum Beispiel $p_{\text{AB}} = p_{\text{A}} · p_{\rm {B\hspace{0.01cm}|\hspace{0.01cm}A}}$. | ||
| − | |||
| Zeile 290: | Zeile 291: | ||
{{BlaueBox|TEXT= | {{BlaueBox|TEXT= | ||
$\text{Fazit:}$ Damit lautet die '''zweite Entropienäherung''' (mit der Einheit „bit/Symbol”): | $\text{Fazit:}$ Damit lautet die '''zweite Entropienäherung''' (mit der Einheit „bit/Symbol”): | ||
| − | :$$H_2 = {1}/{2} \cdot {H_2'} = {1}/{2} \cdot [ H_{\rm 1} + H_{\rm M}] | + | :$$H_2 = {1}/{2} \cdot {H_2\hspace{0.05cm}'} = {1}/{2} \cdot \big [ H_{\rm 1} + H_{\rm M} \big] |
\hspace{0.05cm}.$$}} | \hspace{0.05cm}.$$}} | ||
Anzumerken ist: | Anzumerken ist: | ||
| − | *Der erste Summand | + | *Der erste Summand $H_1$ ⇒ erste Entropienäherung ist allein abhängig von den Symbolwahrscheinlichkeiten. |
| − | *Bei einem symmetrischen Markovprozess ⇒ $p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}B}} = \rm | + | *Bei einem symmetrischen Markovprozess ⇒ $p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}B}} = p_{\rm {B\hspace{0.01cm}|\hspace{0.01cm}A}} $ ⇒ $p_{\text{A}} = p_{\text{B}} = 1/2$ ergibt sich für diesen ersten Summanden $H_1 = 1 \hspace{0.05cm} \rm bit/Symbol$. |
| − | *Der zweite Summand $H_{\text{M}}$ muss gemäß der zweiten der oberen Gleichungen berechnet werden. Bei einem symmetrischen Markovprozess erhält man $H_{\text{M}} = H_{\text{bin}}(p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}B}})$. | + | *Der zweite Summand $H_{\text{M}}$ muss gemäß der zweiten der oberen Gleichungen berechnet werden. |
| + | *Bei einem symmetrischen Markovprozess erhält man $H_{\text{M}} = H_{\text{bin}}(p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}B}})$. | ||
Nun wird dieses Ergebnis auf die $k$–te Entropienäherung erweitert. Hierbei wird der Vorteil von Markovquellen gegenüber anderen Quellen ausgenutzt, dass sich die Entropieberechnung für $k$–Tupel sehr einfach gestaltet. Für jede Markovquelle gilt nämlich: | Nun wird dieses Ergebnis auf die $k$–te Entropienäherung erweitert. Hierbei wird der Vorteil von Markovquellen gegenüber anderen Quellen ausgenutzt, dass sich die Entropieberechnung für $k$–Tupel sehr einfach gestaltet. Für jede Markovquelle gilt nämlich: | ||
| − | :$$H_k = {1}/{k} \cdot [ H_{\rm 1} + (k-1) \cdot H_{\rm M}] \hspace{0.3cm} \Rightarrow \hspace{0.3cm} | + | :$$H_k = {1}/{k} \cdot \big [ H_{\rm 1} + (k-1) \cdot H_{\rm M}\big ] \hspace{0.3cm} \Rightarrow \hspace{0.3cm} |
| − | H_2 = {1}/{2} \cdot [ H_{\rm 1} + H_{\rm M}]\hspace{0.05cm}, \hspace{0.3cm} | + | H_2 = {1}/{2} \cdot \big [ H_{\rm 1} + H_{\rm M} \big ]\hspace{0.05cm}, \hspace{0.3cm} |
| − | H_3 ={1}/{3} \cdot [ H_{\rm 1} + 2 \cdot H_{\rm M}] \hspace{0.05cm},\hspace{0.3cm} | + | H_3 ={1}/{3} \cdot \big [ H_{\rm 1} + 2 \cdot H_{\rm M}\big ] \hspace{0.05cm},\hspace{0.3cm} |
| − | H_4 = {1}/{4} \cdot [ H_{\rm 1} + 3 \cdot H_{\rm M}] | + | H_4 = {1}/{4} \cdot \big [ H_{\rm 1} + 3 \cdot H_{\rm M}\big ] |
\hspace{0.05cm},\hspace{0.15cm}{\rm usw.}$$ | \hspace{0.05cm},\hspace{0.15cm}{\rm usw.}$$ | ||
Version vom 18. September 2018, 16:36 Uhr
Inhaltsverzeichnis
Ein einfaches einführendes Beispiel
$\text{Beispiel 1:}$ Zu Beginn des ersten Kapitels haben wir eine gedächtnislose Nachrichtenquelle mit dem Symbolvorrat $\rm \{A, B, C, D\}$ ⇒ $M = 4$ betrachtet. Eine beispielhafte Symbolfolge ist in der nachfolgenden Grafik als Quelle $\rm Q1$ nochmals dargestellt.
Mit den Symbolwahrscheinlichkeiten $p_{\rm A} = 0.4 \hspace{0.05cm},\hspace{0.2cm}p_{\rm B} = 0.3 \hspace{0.05cm},\hspace{0.2cm}p_{\rm C} = 0.2 \hspace{0.05cm},\hspace{0.2cm} p_{\rm D} = 0.1\hspace{0.05cm}$ ergibt sich die Entropie zu
- $$H \hspace{-0.05cm}= 0.4 \cdot {\rm log}_2\hspace{0.05cm}\frac {1}{0.4} + 0.3 \cdot {\rm log}_2\hspace{0.05cm}\frac {1}{0.3} +0.2 \cdot {\rm log}_2\hspace{0.05cm}\frac {1}{0.2} +0.1 \cdot {\rm log}_2\hspace{0.05cm}\frac {1}{0.1} \approx 1.84 \hspace{0.05cm}{\rm bit/Symbol} \hspace{0.01cm}.$$
Aufgrund der ungleichen Symbolwahrscheinlichkeiten ist die Entropie kleiner als der Entscheidungsgehalt $H_0 = \log_2 M = 2 \hspace{0.05cm} \rm bit/Symbol$.

Die Quelle $\rm Q2$ ist weitgehend identisch mit der Quelle $\rm Q1$, außer, dass jedes einzelne Symbol nicht nur einmal, sondern zweimal nacheinander ausgegeben wird: $\rm A ⇒ AA$, $\rm B ⇒ BB$, usw.
- Es ist offensichtlich, dass $\rm Q2$ eine kleinere Entropie (Unsicherheit) aufweist als $\rm Q1$.
- Aufgrund des einfachen Wiederholungscodes ist nun $H = 1.84/2 = 0.92 \hspace{0.05cm} \rm bit/Symbol$ nur halb so groß,
- obwohl sich an den Auftrittswahrscheinlichkeiten nichts geändert hat.
$\text{Fazit:}$ Dieses Beispiel zeigt:
- Die Entropie einer gedächtnisbehafteten Quelle ist kleiner als die Entropie einer gedächtnislosen Quelle mit gleichen Symbolwahrscheinlichkeiten.
- Es müssen nun auch die statistischen Bindungen innerhalb der Folge $〈 q_ν 〉$ berücksichtigt werden, nämlich die Abhängigkeit des Symbols $q_ν$ von den Vorgängersymbolen $q_{ν–1}$, $q_{ν–2}$, ...
Entropie hinsichtlich Zweiertupel
Wir betrachten weiterhin die Quellensymbolfolge $〈 q_1, \hspace{0.05cm} q_2,\hspace{0.05cm}\text{ ...} \hspace{0.05cm}, q_{ν–1}, \hspace{0.05cm}q_ν, \hspace{0.05cm}\hspace{0.05cm}q_{ν+1} ,\hspace{0.05cm}\text{ ...} \hspace{0.05cm}〉$ und betrachten nun die Entropie zweier aufeinanderfolgender Quellensymbole.
- Alle Quellensymbole $q_ν$ entstammen einem Alphabet mit dem Symbolunfang $M$, so dass es für die Kombination $(q_ν, \hspace{0.05cm}q_{ν+1})$ genau $M^2$ mögliche Symbolpaare mit folgenden Verbundwahrscheinlichkeiten gibt:
- $${\rm Pr}(q_{\nu}\cap q_{\nu+1})\le {\rm Pr}(q_{\nu}) \cdot {\rm Pr}( q_{\nu+1}) \hspace{0.05cm}.$$
- Daraus ist die Verbundentropie eines Zweier–Tupels berechenbar:
- $$H_2\hspace{0.05cm}' = \sum_{q_{\nu}\hspace{0.05cm} \in \hspace{0.05cm}\{ \hspace{0.05cm}q_{\mu}\hspace{0.01cm} \}} \sum_{q_{\nu+1}\hspace{0.05cm} \in \hspace{0.05cm}\{ \hspace{0.05cm} q_{\mu}\hspace{0.01cm} \}}\hspace{-0.1cm}{\rm Pr}(q_{\nu}\cap q_{\nu+1}) \cdot {\rm log}_2\hspace{0.1cm}\frac {1}{{\rm Pr}(q_{\nu}\cap q_{\nu+1})} \hspace{0.4cm}({\rm Einheit\hspace{-0.1cm}: \hspace{0.1cm}bit/Zweiertupel}) \hspace{0.05cm}.$$
- Der Index „2” symbolisiert, dass sich die so berechnete Entropie auf Zweiertupel bezieht.
Um den mittleren Informationsgehalt pro Symbol zu erhalten, muss $H_2\hspace{0.05cm}'$ noch halbiert werden:
- $$H_2 = {H_2\hspace{0.05cm}'}/{2} \hspace{0.5cm}({\rm Einheit\hspace{-0.1cm}: \hspace{0.1cm}bit/Symbol}) \hspace{0.05cm}.$$
Um eine konsistente Nomenklatur zu erreichen, benennen wir nun die im Kapitel Gedächtnislose Nachrichtenquellen definierte Entropie mit $H_1$:
- $$H_1 = \sum_{q_{\nu}\hspace{0.05cm} \in \hspace{0.05cm}\{ \hspace{0.05cm}q_{\mu}\hspace{0.01cm} \}} {\rm Pr}(q_{\nu}) \cdot {\rm log_2}\hspace{0.1cm}\frac {1}{{\rm Pr}(q_{\nu})} \hspace{0.5cm}({\rm Einheit\hspace{-0.1cm}: \hspace{0.1cm}bit/Symbol}) \hspace{0.05cm}.$$
Der Index „1” soll darauf hinweisen, dass $H_1$ ausschließlich die Symbolwahrscheinlichkeiten berücksichtigt und nicht statistischen Bindungen zwischen Symbolen innerhalb der Folge. Mit dem Entscheidungsgehalt $H_0 = \log_2 \ M$ ergibt sich dann folgende Größenbeziehung:
- $$H_0 \ge H_1 \ge H_2 \hspace{0.05cm}.$$
Bei statistischer Unabhängigkeit der Folgenelemente ist $H_2 = H_1$.
Die bisherigen Gleichungen geben jeweils einen Scharmittelwert an. Die für die Berechnung von $H_1$ und $H_2$ benötigten Wahrscheinlichkeiten lassen sich aber auch als Zeitmittelwerte aus einer sehr langen Folge berechnen oder – etwas genauer ausgedrückt – durch die entsprechenden relativen Häufigkeiten annähern.
Verdeutlichen wir uns nun die Berechnung der Entropienäherungen $H_1$ und $H_2$ an drei Beispielen.
$\text{Beispiel 2:}$ Wir betrachten zunächst die Folge $〈 q_1$, ... , $q_{50} \rangle $ gemäß folgernder Grafik, wobei die Folgenelemente $q_ν$ dem Alphabet $\rm \{A, B, C \}$ entstammen ⇒ der Symbolumfang ist $M = 3$.

Durch Zeitmittelung über die $50$ Symbole erhält man die Symbolwahrscheinlichkeiten $p_{\rm A} ≈ 0.5$, $p_{\rm B} ≈ 0.3$ und $p_{\rm C} ≈ 0.2$, womit man die Entropienäherung erster Ordnung berechnen kann:
- $$H_1 = 0.5 \cdot {\rm log}_2\hspace{0.1cm}\frac {1}{0.5} + 0.3 \cdot {\rm log}_2\hspace{0.1cm}\frac {1}{0.3} +0.2 \cdot {\rm log}_2\hspace{0.1cm}\frac {1}{0.2} \approx \, 1.486 \,{\rm bit/Symbol} \hspace{0.05cm}.$$
Aufgrund der nicht gleichwahrscheinlichen Symbole ist $H_1 < H_0 = 1.585 \hspace{0.05cm} \rm bit/Symbol$. Als Näherung für die Wahrscheinlichkeiten von Zweiertupeln erhält man aus der obigen Folge:
- $$\begin{align*}p_{\rm AA} \hspace{-0.1cm}& = \hspace{-0.1cm} 14/49\hspace{0.05cm}, \hspace{0.2cm}p_{\rm AB} = 8/49\hspace{0.05cm}, \hspace{0.2cm}p_{\rm AC} = 3/49\hspace{0.05cm}, \\ p_{\rm BA} \hspace{-0.1cm}& = \hspace{0.07cm} 7/49\hspace{0.05cm}, \hspace{0.25cm}p_{\rm BB} = 2/49\hspace{0.05cm}, \hspace{0.2cm}p_{\rm BC} = 5/49\hspace{0.05cm}, \\ p_{\rm CA} \hspace{-0.1cm}& = \hspace{0.07cm} 4/49\hspace{0.05cm}, \hspace{0.25cm}p_{\rm CB} = 5/49\hspace{0.05cm}, \hspace{0.2cm}p_{\rm CC} = 1/49\hspace{0.05cm}.\end{align*}$$
Beachten Sie, dass aus den $50$ Folgenelementen nur $49$ Zweiertupel $(\rm AA$, ... , $\rm CC)$ gebildet werden können, die in obiger Grafik farblich unterschiedlich markiert sind.
- Die daraus berechenbare Entropienäherung $H_2$ sollte eigentlich gleich $H_1$ sein, da die gegebene Symbolfolge von einer gedächtnislosen Quelle stammt.
- Aufgrund der kurzen Folgenlänge $N = 50$ und der daraus resultierenden statistischen Ungenauigkeit ergibt sich aber ein kleinerer Wert: $H_2 ≈ 1.39\hspace{0.05cm} \rm bit/Symbol$.
$\text{Beispiel 3:}$ Nun betrachten wir eine gedächtnislose Binärquelle mit gleichwahrscheinlichen Symbolen, das heißt es gelte $p_{\rm A} = p_{\rm B} = 1/2$. Die ersten zwanzig Folgeelemente lauten: $〈 q_ν 〉 =\rm BBAAABAABBBBBAAAABAB$ ...
- Aufgrund der gleichwahrscheinlichen Binärsymbole ist $H_1 = H_0 = 1 \hspace{0.05cm} \rm bit/Symbol$.
- Die Verbundwahrscheinlichkeit $p_{\rm AB}$ der Kombination $\rm AB$ ist gleich $p_{\rm A} · p_{\rm B} = 1/4$. Ebenso gilt $p_{\rm AA} = p_{\rm BB} = p_{\rm BA} = 1/4$.
- Damit erhält man für die zweite Entropienäherung
- $$H_2 = {1}/{2} \cdot \big [ {1}/{4} \cdot {\rm log}_2\hspace{0.1cm}4 + {1}/{4} \cdot {\rm log}_2\hspace{0.1cm}4 +{1}/{4} \cdot {\rm log}_2\hspace{0.1cm}4 +{1}/{4} \cdot {\rm log}_2\hspace{0.1cm}4 \big ] = 1 \,{\rm bit/Symbol} = H_1 = H_0 \hspace{0.05cm}.$$
Hinweis: Aus der oben angegebenen Folge ergeben sich aufgrund der kurzen Länge etwas andere Verbundwahrscheinlichkeiten, nämlich $p_{\rm AA} = 6/19$, $p_{\rm BB} = 5/19$ und $p_{\rm AB} = p_{\rm BA} = 4/19$.
$\text{Beispiel 4:}$ Die dritte hier betrachtete Folge ergibt sich aus der Folge von $\text{Beispiel 3}$ durch Anwendung eines einfachen Wiederholungscodes:
- $$〈 q_ν 〉 =\rm BbBbAaAaAaBbAaAaBbBb \text{...} $$
- Die wiederholten Symbole sind durch entsprechende Kleinbuchstaben markiert.
- Aufgrund der gleichwahrscheinlichen Binärsymbole ergibt sich auch hier $H_1 = H_0 = 1 \hspace{0.05cm} \rm bit/Symbol$.
- Wie in Aufgabe 1.3 gezeigt wird, gilt nun für die Verbundwahrscheinlichkeiten $p_{\rm AA}=p_{\rm BB} = 3/8$ und $p_{\rm ABA}=p_{\rm BAB} = 1/8$. Daraus folgt:
- $$\begin{align*}H_2 ={1}/{2} \cdot \big [ 2 \cdot {3}/{8} \cdot {\rm log}_2\hspace{0.1cm} {8}/{3} + 2 \cdot {1}/{8} \cdot {\rm log}_2\hspace{0.1cm}8\big ] = {3}/{8} \cdot {\rm log}_2\hspace{0.1cm}8 - {3}/{8} \cdot{\rm log}_2\hspace{0.1cm}3 + {1}/{8} \cdot {\rm log}_2\hspace{0.1cm}8 \approx 0.906 \,{\rm bit/Symbol} < H_1 = H_0 \hspace{0.05cm}.\end{align*}$$
Betrachtet man sich die Aufgabenstellung genauer, so kommt man zu folgendem Schluss:
- Die Entropie müsste eigentlich $H = 0.5 \hspace{0.05cm} \rm bit/Symbol$ sein (jedes zweite Symbol liefert keine neue Information).
- Die zweite Entropienäherung $H_2 = 0.906 \hspace{0.05cm} \rm bit/Symbol$ ist aber deutlich größer als die Entropie $H$.
- Zur Entropiebestimmung reicht die Näherung zweiter Ordnung nicht aus. Vielmehr muss man größere zusammenhängende Blöcke mit $k > 2$ Symbolen betrachten.
- Einen solchen Block bezeichnen wir im Folgenden als $k$–Tupel.
Verallgemeinerung auf $k$–Tupel und Grenzübergang
Zur Abkürzung schreiben wir mit der Verbundwahrscheinlichkeit $p_i^{(k)}$ eines $k$–Tupels allgemein:
- $$H_k = \frac{1}{k} \cdot \sum_{i=1}^{M^k} p_i^{(k)} \cdot {\rm log}_2\hspace{0.1cm} \frac{1}{p_i^{(k)}} \hspace{0.5cm}({\rm Einheit\hspace{-0.1cm}: \hspace{0.1cm}bit/Symbol}) \hspace{0.05cm}.$$
Die Laufvariable $i$ steht jeweils für eines der $M^k$ Tupel. Die vorher berechnete Näherung $H_2$ ergibt sich mit $k = 2$.
$\text{Definition:}$ Die Entropie einer Nachrichtenquelle mit Gedächtnis ist der folgende Grenzwert:
- $$H = \lim_{k \rightarrow \infty }H_k \hspace{0.05cm}.$$
Für die Entropienäherungen $H_k$ gelten folgende Größenrelationen ($H_0$ ist der Entscheidungsgehalt):
- $$H \le \text{...} \le H_k \le \text{...} \le H_2 \le H_1 \le H_0 \hspace{0.05cm}.$$
Der Rechenaufwand wird bis auf wenige Sonderfälle (siehe nachfolgendes Beispiel) mit zunehmendem $k$ immer größer und hängt natürlich auch vom Symbolumfang $M$ ab:
- Zur Berechnung von $H_{10}$ einer Binärquelle $(M = 2)$ ist über $2^{10} = 1024$ Terme zu mitteln.
- Mit jeder weiteren Erhöhung von $k$ um $1$ verdoppelt sich die Anzahl der Summenterme.
- Bei einer Quaternärquelle $(M = 4)$ muss zur $H_{10}$–Bestimmung bereits über $4^{10} = 1\hspace{0.08cm}048\hspace{0.08cm}576$ Summenterme gemittelt werden.
- Berücksichtigt man, dass jedes dieser $4^{10} =2^{20} >10^6$ $k$–Tupel bei Simulation/Zeitmittelung etwa $100$ mal (statistischer Richtwert) vorkommen sollte, um ausreichende Simulationsgenauigkeit zu gewährleisten, so folgt daraus, dass die Folgenlänge größer als $N = 10^8$ sein sollte.
$\text{Beispiel 5:}$ Wir betrachten eine alternierende Binärfolge ⇒ $〈 q_ν 〉 =\rm ABABABAB$ ... . Entsprechend gilt $H_0 = H_1 = 1 \hspace{0.05cm} \rm bit/Symbol$.
In diesem Sonderfall muss zur Bestimmung der $H_k$–Näherung unabhängig von $k$ stets nur über zwei Verbundwahrscheinlichkeiten gemittelt werden:
- $k = 2$: $p_{\rm AB} = p_{\rm BA} = 1/2$ ⇒ $H_2 = 1/2 \hspace{0.1cm} \rm bit/Symbol$,
- $k = 3$: $p_{\rm ABA} = p_{\rm BAB} = 1/2$ ⇒ $H_3 = 1/3 \hspace{0.1cm} \rm bit/Symbol$,
- $k = 4$: $p_{\rm ABAB} = p_{\rm BABA} = 1/2$ ⇒ $H_4 = 1/4 \hspace{0.1cm} \rm bit/Symbol$.
Die (tatsächliche) Entropie dieser alternierenden Binärfolge ist demzufolge
- $$H = \lim_{k \rightarrow \infty }{1}/{k} = 0 \hspace{0.05cm}.$$
Dieses Ergebnis war zu erwarten, da die betrachtete Folge nur minimale Information besitzt, die sich allerdings im Entropie–Endwert $H$ nicht auswirkt, nämlich die Information: „Tritt $\rm A$ zu den geraden oder ungeraden Zeitpunkten auf?”
Man erkennt, dass $H_k$ diesem Endwert $H = 0$ nur sehr langsam näher kommt: Die zwanzigste Entropienäherung liefert immer noch $H_{20} = 0.05 \hspace{0.05cm} \rm bit/Symbol$.
$\text{Zusammenfassung der Ergebnisse der letzten Seiten:}$
- Allgemein gilt für die Entropie einer Nachrichtenquelle:
- $$H \le \text{...} \le H_3 \le H_2 \le H_1 \le H_0 \hspace{0.05cm}.$$
- Eine redundanzfreie Quelle liegt vor, falls alle $M$ Symbole gleichwahrscheinlich sind und es keine statistischen Bindungen innerhalb der Folge gibt.
Für diese gilt ( $r$ bezeichnet hierbei die relative Redundanz ):
- $$H = H_0 = H_1 = H_2 = H_3 = \text{...}\hspace{0.5cm} \Rightarrow \hspace{0.5cm} r = \frac{H - H_0}{H_0}= 0 \hspace{0.05cm}.$$
- Eine gedächtnislose Quelle kann durchaus redundant sein $(r> 0)$. Diese Redundanz geht dann allein auf die Abweichung der Symbolwahrscheinlichkeiten von der Gleichverteilung zurück. Hier gelten folgende Relationen:
- $$H = H_1 = H_2 = H_3 = \text{...} \le H_0 \hspace{0.5cm}\Rightarrow \hspace{0.5cm}0 \le r = \frac{H_1 - H_0}{H_0}< 1 \hspace{0.05cm}.$$
- Die entsprechende Bedingung für eine gedächtnisbehaftete Quelle lautet:
- $$ H <\text{...} < H_3 < H_2 < H_1 \le H_0 \hspace{0.5cm}\Rightarrow \hspace{0.5cm} 0 < r = \frac{H_1 - H_0}{H_0}\le1 \hspace{0.05cm}.$$
- Ist $H_2 < H_1$, dann gilt auch $H_3 < H_2$, $H_4 < H_3$, usw. ⇒ In der allgemeinen Gleichung ist also das „≤”–Zeichen durch das „<”–Zeichen zu ersetzen.
- Sind die Symbole gleichwahrscheinlich, so gilt wieder $H_1 = H_0$, während bei nicht gleichwahrscheinlichen Symbolen $H_1 < H_0$ zutrifft.
Die Entropie des AMI–Codes
Im Kapitel Symbolweise Codierung mit Pseudoternärcodes des Buches „Digitalsignalübertragung” wird unter Anderem der AMI–Pseudoternärcode behandelt.
- Dieser wandelt die Binärfolge $〈 q_ν 〉$ mit $q_ν ∈ \{ \rm L, H \}$ in die Ternärfolge $〈 c_ν 〉$ mit $q_ν ∈ \{ \rm M, N, P \}$.
- Die Bezeichnungen der Quellensymbole stehen für $\rm L$ow und $\rm H$igh und die der Codesymbole für $\rm M$inus, $\rm N$ull und $\rm P$lus”
Die Codierregel des AMI–Codes (diese Kurzform steht für „Alternate Mark Inversion”) lautet:
- Jedes Binärsymbol $q_ν =\rm L$ wird durch das Codesymbol $c_ν =\rm N$ dargestellt.
- Dagegen wird $q_ν =\rm H$ abwechselnd mit $c_ν =\rm P$ und $c_ν =\rm M$ codiert ⇒ Name „AMI”.
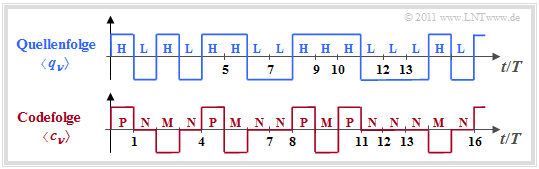 Signale und Symbolfolgen beim AMI–Code
Signale und Symbolfolgen beim AMI–Code

Durch die Codierung wird Redundanz hinzugefügt, allein mit dem Ziel, dass die Codefolge keinen Gleichsignalanteil beinhaltet.
Wir betrachten hier jedoch nicht die spektralen Eigenschaften des AMI–Codes, sondern interpretieren diesen Code informationstheoretisch:
- Aufgrund der Stufenzahl $M = 3$ ist der Entscheidungsgehalt der (ternären) Codefolge gleich $H_0 = \log_2 \ 3 ≈ 1.585 \hspace{0.05cm} \rm bit/Symbol$. Die erste Entropienäherung liefert $H_1 = 1.5 \hspace{0.05cm} \rm bit/Symbol$, wie die nachfolgende Rechnung zeigt:
- $$p_{\rm H} = p_{\rm L} = 1/2 \hspace{0.3cm}\Rightarrow \hspace{0.3cm} p_{\rm N} = p_{\rm L} = 1/2\hspace{0.05cm},\hspace{0.2cm}p_{\rm M} = p_{\rm P}= p_{\rm H}/2 = 1/4\hspace{0.3cm} \Rightarrow \hspace{0.3cm} H_1 = 1/2 \cdot {\rm log}_2\hspace{0.1cm}2 + 2 \cdot 1/4 \cdot{\rm log}_2\hspace{0.1cm}4 = 1.5 \,{\rm bit/Symbol} \hspace{0.05cm}.$$
- Betrachten wir nun Zweiertupel. Beim AMI–Code kann $\rm P$ nicht auf $\rm P$ und $\rm M$ nicht auf $\rm M$ folgen. Die Wahrscheinlichkeit für $\rm NN$ ist gleich $p_{\rm L} · p_{\rm L} = 1/4$. Alle anderen (sechs) Zweiertupel treten mit der Wahrscheinlichkeit $1/8$ auf. Daraus folgt für die zweite Entropienäherung:
- $$H_2 = 1/2 \cdot \big [ 1/4 \cdot {\rm log_2}\hspace{0.1cm}4 + 6 \cdot 1/8 \cdot {\rm log_2}\hspace{0.1cm}8 \big ] = 1.375 \,{\rm bit/Symbol} \hspace{0.05cm}.$$
- Für die weiteren Entropienäherungen $H_3$, $H_43$, ... und die tatsächliche Entropie $H$ wird gelten:
- $$ H < \hspace{0.05cm}\text{...}\hspace{0.05cm} < H_5 < H_4 < H_3 < H_2 = 1.375 \,{\rm bit/Symbol} \hspace{0.05cm}.$$
- Bei diesem Beispiel kennt man ausnahmsweisedie tatsächliche Entropie $H$ der Codesymbolfolge $〈 c_ν 〉$: Da durch den Coder keine neue Information hinzukommt, aber auch keine verloren geht, ergibt sich die gleiche Entropie $H = 1 \,{\rm bit/Symbol} $ wie für die redundanzfreie Binärfolge $〈 q_ν 〉$.
Die Aufgabe 1.4 zeigt den bereits beträchtlichen Aufwand zur Berechnung der Entropienäherung $H_3$. Zudem weicht $H_3$ noch deutlich vom Endwert $H = 1 \,{\rm bit/Symbol} $ ab.
Schneller kommt man zum Ergebnis, wenn man den AMI–Code durch eine Markovkette beschreibt, wie im nächsten Abschnitt dargelegt.
Binärquellen mit Markoveigenschaften

Folgen mit statistischen Bindungen zwischen den Folgenelementen (Symbolen) werden oft durch Markovprozesse modelliert, wobei wir uns hier auf Markovprozesse erster Ordnung beschränken. Zunächst betrachten wir einen binären Markovprozess $(M = 2)$ mit den Zuständen (Symbolen) $\rm A$ und $\rm B$.
Rechts sehen Sie das Übergangsdiagramm für einen binären Markovprozess erster Ordnung. Von den vier angegebenen Übertragungswahrscheinlichkeiten sind allerdings nur zwei frei wählbar, zum Beispiel
- $p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}B}} = \rm Pr(A\hspace{0.01cm}|\hspace{0.01cm}B)$ ⇒ bedingte Wahrscheinlichkeit, dass $\rm A$ auf $\rm B$ folgt.
- $p_{\rm {B\hspace{0.01cm}|\hspace{0.01cm}A}} = \rm Pr(B\hspace{0.01cm}|\hspace{0.01cm}A)$ ⇒ bedingte Wahrscheinlichkeit, dass $\rm B$ auf $\rm A$ folgt.
Für die beiden weiteren Übergangswahrscheinlichkeiten gilt dann $p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}A} = 1- p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}A}$ und $p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}B} = 1- p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}B}
\hspace{0.05cm}.$
Aufgrund der vorausgesetzten Eigenschaften Stationarität und Ergodizität gilt für die Zustands– bzw. Symbolwahrscheinlichkeiten:
- $$p_{\rm A} = {\rm Pr}({\rm A}) = \frac{p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}B}}{p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}B} + p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}A}} \hspace{0.05cm}, \hspace{0.2cm}p_{\rm B} = {\rm Pr}({\rm B}) = \frac{p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}A}}{p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}B} + p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}A}} \hspace{0.05cm}.$$
Diese Gleichungen erlauben erste informationstheoretische Aussagen über Markovprozesse:
- Für $p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}B}} = p_{\rm {B\hspace{0.01cm}|\hspace{0.01cm}A}}$ sind die Symbole gleichwahrscheinlich ⇒ $p_{\text{A}} = p_{\text{B}}= 0.5$. Die erste Entropienäherung liefert $H_1 = H_0 = 1 \hspace{0.05cm} \rm bit/Symbol$, und zwar unabhängig von den tatsächlichen Werten der (bedingten) Übergangswahrscheinlichkeiten $p_{\text{A|B}}$ bzw. $p_{\text{B|A}}$.
- Die Quellenentropie $H$ als der Grenzwert (für $k \to \infty$) der Entropienäherung $k$–ter Ordnung ⇒ $H_k$ hängt aber sehr wohl von den tatsächlichen Werten von $p_{\text{A|B}}$ und $p_{\text{B|A}}$ ab und nicht nur von ihrem Quotienten. Dies zeigt das folgende Beispiel.
$\text{Beispiel 6:}$ Wir betrachten drei binäre symmetrische Markovquellen, die sich durch die Zahlenwerte der symmetrischen Übergangswahrscheinlichkeiten $p_{\rm {A\hspace{0.01cm}\vert\hspace{0.01cm}B} } = p_{\rm {B\hspace{0.01cm}\vert\hspace{0.01cm}A} }$ unterscheiden. Für die Symbolwahrscheinlichkeiten gilt somit $p_{\rm A} = p_{\rm B}= 0.5,$ und die anderen Übergangswahrscheinlichkeiten haben dann die Werte

- $$p_{\rm {A\hspace{0.01cm}\vert\hspace{0.01cm}A} } = 1 - p_{\rm {B\hspace{0.01cm}\vert\hspace{0.01cm}A} } = p_{\rm {B\hspace{0.01cm}\vert\hspace{0.01cm}B} }.$$
- Die mittlere (blaue) Symbolfolge mit $p_{\rm {A\hspace{0.01cm}\vert\hspace{0.01cm}B} } = p_{\rm {B\hspace{0.01cm}\vert\hspace{0.01cm}A} } = 0.5$ besitzt die Entropie $H ≈ 1 \hspace{0.05cm} \rm bit/Symbol$. Das heißt: In diesem Sonderfall gibt es keine statistischen Bindungen innerhalb der Folge.
- Die linke (rote) Folge mit $p_{\rm {A\hspace{0.01cm}\vert\hspace{0.01cm}B} } = p_{\rm {B\hspace{0.01cm}\vert\hspace{0.01cm}A} } = 0.25$ weist weniger Wechsel zwischen $\rm A$ und $\rm B$ auf. Aufgrund von statistischen Abhängigkeiten zwischen benachbarten Symbolen ist nun $H ≈ 0.72 \hspace{0.05cm} \rm bit/Symbol$ kleiner.
- Die rechte (grüne) Symbolfolge mit $p_{\rm {A\hspace{0.01cm}\vert\hspace{0.01cm}B} } = p_{\rm {B\hspace{0.01cm}\vert\hspace{0.01cm}A} } = 0.8$ hat die genau gleiche Entropie $H ≈ 0.72 \hspace{0.05cm} \rm bit/Symbol$ wie die rote Folge. Hier erkennt man viele Bereiche mit sich stets abwechselnden Symbolen (... $\rm ABABAB$ ... ).
Zu diesem Beispiel ist noch anzumerken:
- Hätte man nicht die Markoveigenschaften der roten und der grünen Folge ausgenutzt, so hätte man das Ergebnis $H ≈ 0.72 \hspace{0.05cm} \rm bit/Symbol$ erst nach langwierigen Berechnungen erhalten.
- Auf den nächsten Seiten wird gezeigt, dass bei einer Quelle mit Markoveigenschaften der Endwert $H$ allein aus den Entropienäherungen $H_1$ und $H_2$ ermittelt werden kann. Ebenso lassen sich aus $H_1$ und $H_2$ alle Entropienäherungen $H_k$ für $k$–Tupel in einfacher Weise berechnen ⇒ $H_3$, $H_4$, $H_5$, ... , $H_{100}$, ...
Vereinfachte Entropieberechnung bei Markovquellen
Wir gehen weiterhin von der symmetrischen binären Markovquelle erster Ordnung aus. Wie auf der vorherigen Seite verwenden wir folgende Nomenklatur für
- die Übergangswahrscheinlichkeiten $p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}B}}$, $p_{\rm {B\hspace{0.01cm}|\hspace{0.01cm}A}}$, $p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}A}}= 1- p_{\rm {B\hspace{0.01cm}|\hspace{0.01cm}A}}$, $p_{\rm {B\hspace{0.01cm}|\hspace{0.01cm}B}} = 1 - p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}B}}$,
- die ergodischen Wahrscheinlichkeiten $p_{\text{A}}$ und $p_{\text{B}}$,
- die Verbundwahrscheinlichkeiten, zum Beispiel $p_{\text{AB}} = p_{\text{A}} · p_{\rm {B\hspace{0.01cm}|\hspace{0.01cm}A}}$.
Wir berechnen nun die Entropie eines Zweiertupels (mit der Einheit „bit/Zweiertupel”):
- $$H_2\hspace{0.05cm}' = p_{\rm A} \cdot p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}A} \cdot {\rm log}_2\hspace{0.1cm}\frac {1}{ p_{\rm A} \cdot p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}A}} + p_{\rm A} \cdot p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}A} \cdot {\rm log}_2\hspace{0.1cm}\frac {1}{ p_{\rm A} \cdot p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}A}} + p_{\rm B} \cdot p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}B} \cdot {\rm log}_2\hspace{0.1cm}\frac {1}{ p_{\rm B} \cdot p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}B}} + p_{\rm B} \cdot p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}B} \cdot {\rm log}_2\hspace{0.1cm}\frac {1}{ p_{\rm B} \cdot p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}B}} \hspace{0.05cm}.$$
Ersetzt man nun die Logarithmen der Produkte durch entsprechende Summen von Logarithmen, so erhält man das Ergebnis $H_2\hspace{0.05cm}' = H_1 + H_{\text{M}}$ mit
- $$H_1 = p_{\rm A} \cdot (p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}A} + p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}A})\cdot {\rm log}_2\hspace{0.1cm}\frac {1}{p_{\rm A}} + p_{\rm B} \cdot (p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}B} + p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}B})\cdot {\rm log}_2\hspace{0.1cm}\frac {1}{p_{\rm B}} = p_{\rm A} \cdot {\rm log}_2\hspace{0.1cm}\frac {1}{p_{\rm A}} + p_{\rm B} \cdot {\rm log}_2\hspace{0.1cm}\frac {1}{p_{\rm B}} = H_{\rm bin} (p_{\rm A})= H_{\rm bin} (p_{\rm B}) \hspace{0.05cm},$$
- $$H_{\rm M}= p_{\rm A} \cdot p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}A} \cdot {\rm log}_2\hspace{0.1cm}\frac {1}{ p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}A}} + p_{\rm A} \cdot p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}A} \cdot {\rm log}_2\hspace{0.1cm}\frac {1}{ p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}A}} + p_{\rm B} \cdot p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}B} \cdot {\rm log}_2\hspace{0.1cm}\frac {1}{ p_{\rm A\hspace{0.01cm}|\hspace{0.01cm}B}} + p_{\rm B} \cdot p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}B} \cdot {\rm log}_2\hspace{0.1cm}\frac {1}{ p_{\rm B\hspace{0.01cm}|\hspace{0.01cm}B}} \hspace{0.05cm}.$$
$\text{Fazit:}$ Damit lautet die zweite Entropienäherung (mit der Einheit „bit/Symbol”):
- $$H_2 = {1}/{2} \cdot {H_2\hspace{0.05cm}'} = {1}/{2} \cdot \big [ H_{\rm 1} + H_{\rm M} \big] \hspace{0.05cm}.$$
Anzumerken ist:
- Der erste Summand $H_1$ ⇒ erste Entropienäherung ist allein abhängig von den Symbolwahrscheinlichkeiten.
- Bei einem symmetrischen Markovprozess ⇒ $p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}B}} = p_{\rm {B\hspace{0.01cm}|\hspace{0.01cm}A}} $ ⇒ $p_{\text{A}} = p_{\text{B}} = 1/2$ ergibt sich für diesen ersten Summanden $H_1 = 1 \hspace{0.05cm} \rm bit/Symbol$.
- Der zweite Summand $H_{\text{M}}$ muss gemäß der zweiten der oberen Gleichungen berechnet werden.
- Bei einem symmetrischen Markovprozess erhält man $H_{\text{M}} = H_{\text{bin}}(p_{\rm {A\hspace{0.01cm}|\hspace{0.01cm}B}})$.
Nun wird dieses Ergebnis auf die $k$–te Entropienäherung erweitert. Hierbei wird der Vorteil von Markovquellen gegenüber anderen Quellen ausgenutzt, dass sich die Entropieberechnung für $k$–Tupel sehr einfach gestaltet. Für jede Markovquelle gilt nämlich:
- $$H_k = {1}/{k} \cdot \big [ H_{\rm 1} + (k-1) \cdot H_{\rm M}\big ] \hspace{0.3cm} \Rightarrow \hspace{0.3cm} H_2 = {1}/{2} \cdot \big [ H_{\rm 1} + H_{\rm M} \big ]\hspace{0.05cm}, \hspace{0.3cm} H_3 ={1}/{3} \cdot \big [ H_{\rm 1} + 2 \cdot H_{\rm M}\big ] \hspace{0.05cm},\hspace{0.3cm} H_4 = {1}/{4} \cdot \big [ H_{\rm 1} + 3 \cdot H_{\rm M}\big ] \hspace{0.05cm},\hspace{0.15cm}{\rm usw.}$$
$\text{Fazit:}$ Bildet man den Grenzübergang für $k \to \infty$, so erhält man für die tatsächliche Quellenentropie:
- $$H = \lim_{k \rightarrow \infty } H_k = H_{\rm M} \hspace{0.05cm}.$$
Aus diesem einfachen Ergebnis folgen wichtige Erkenntnisse für die Entropieberechnung:
- Bei Markovquellen genügt die Bestimmung der Entropienäherungen $H_1$ und $H_2$. Damit lautet die Entropie einer Markovquelle:
- $$H = 2 \cdot H_2 - H_{\rm 1} \hspace{0.05cm}.$$
- Durch $H_1$ und $H_2$ liegen auch alle weiteren Entropienäherungen $H_k$ für $k \ge 3$ fest:
- $$H_k = \frac{2-k}{k} \cdot H_{\rm 1} + \frac{2\cdot (k-1)}{k} \cdot H_{\rm 2} \hspace{0.05cm}.$$
Diese Näherungen haben allerdings keine große Bedeutung. Wichtig ist meist nur der Grenzwert $H$. Bei Quellen ohne Markoveigenschaften berechnet man die Näherungen $H_k$ nur deshalb, um den Grenzwert, also die tatsächliche Entropie, abschätzen zu können.
Hinweise:
- In der Aufgabe 1.5 werden die obigen Gleichungen auf den allgemeineren Fall einer unsymmetrischen Binärquelle angewendet.
- Alle Gleichungen auf dieser Seite gelten auch für nichtbinäre Markovquellen $(M > 2)$, wie auf der nächsten Seite gezeigt wird.
Nichtbinäre Markovquellen
Für jede Markovquelle gelten unabhängig vom Symbolumfang die folgenden Gleichungen:
- $$H = 2 \cdot H_2 - H_{\rm 1} \hspace{0.05cm},\hspace{0.3cm} H_k = {1}/{k} \cdot [ H_{\rm 1} + (k-1) \cdot H_{\rm M}] \hspace{0.05cm},\hspace{0.3cm} \lim_{k \rightarrow \infty } H_k = H \hspace{0.05cm}.$$
Diese ermöglichen die einfache Berechnung der Entropie $H$ aus den Näherungen $H_1$ und $H_2$.
Wir betrachten nun eine ternäre Markovquelle $\rm MQ3$ (Stufenzahl $M = 3$, blaue Farbgebung) und eine quaternäre Markovquelle $\rm MQ4$ ($M = 4$, rot ) entsprechend den obigen Übergangsdiagrammen.

In Aufgabe 1.6 werden die Entropienäherungen $H_k$ und die Quellenentropie $H$ als der Grenzwert von $H_k$ für $k \to \infty$ berechnet. Die Ergebnisse sind in der folgenden Grafik zusammengestellt. Alle dort angegebenen Entropien haben die Einheit „bit/Symbol”.

Diese Ergebnisse können wie folgt interpretiert werden:
- Bei der ternären Markovquelle $\rm MQ3$ nehmen die Entropienäherungen von $H_1 = 1.500$ über $H_2 = 1.375$ bis zum Grenzwert $H = 1.250$ kontinuierlich ab. Wegen $M = 3$ beträgt der Entscheidungsgehalt $H_0 = 1.585$.
- Für die quaternäre Markovquelle $\rm MQ4$ erhält man $H_0 = H_1 = 2.000$ (da vier gleichwahrscheinliche Zuständen) und $H_2$ = 1.5. Aus dem $H_1$– und $H_2$–Wert lassen sich auch hier alle Entropienäherungen $H_k$ und der Endwert $H = 1.000$ berechnen.
- Die beiden Quellenmodelle $\rm MQ3$ und $\rm MQ4$ entstanden bei dem Versuch, den AMI–Code informationstheoretisch durch Markovquellen zu beschreiben. Die Symbole $\rm M$, $\rm N$ und $\rm P$ stehen hierbei für „Minus”, „Null” und „Plus”.
- Die Entropienäherungen $H_1$, $H_2$ und $H_3$ des AMI–Codes (grüne Markierungen) wurden in Aufgabe A1.4 berechnet. Auf die Berechnung von $H_4$, $H_5$, ... musste aus Aufwandsgründen verzichtet werden. Bekannt ist aber der Endwert von $H_k$ für $k \to \infty$ ⇒ $H = 1.000$.
- Man erkennt, dass das Markovmodell $\rm MQ3$ bezüglich $H_0 = 1.585$, $H_1 = 1.5$ und $H_2 = 1.375$ genau gleiche Zahlenwerte liefert wie der AMI–Code. Dagegen unterscheiden sich $H_3$ ($1.333$ statt $1.292$) und insbesondere der Endwert $H$ ($1.250$ gegenüber $1.000$).
- Das Modell $\rm MQ4$ ($M = 4$) unterscheidet sich vom AMI–Code ($M = 3$) hinsichtlich des Entscheidungsgehaltes $H_0$ und auch bezüglich aller Entropienäherungen $H_k$. Trotzdem ist $\rm MQ4$ das geeignete Modell für den AMI–Code, da der Endwert $H = 1.000$ übereinstimmt.
- Das Modell MQ3 liefert zu große Entropiewerte, da hier die Folgen $\rm PNP$ und $\rm MNM$ möglich sind, die beim AMI–Code nicht auftreten können. Bereits bei der Näherung $H_3$ macht sich der Unterschied geringfügig bemerkbar, im Endwert $H$ sogar deutlich (1.25 statt 1).
Beim Modell $\rm MQ4$ wurde der Zustand „Null” aufgespalten in zwei Zustände $\rm N$ und $\rm O$ (siehe rechte obere Grafik auf dieser Seite):
- Hierbei gilt für den Zustand $\rm N$: Das aktuelle Binärsymbol $\rm L$ wird mit dem Amplitudenwert „0” dargestellt, wie es der AMI–Regel entspricht. Das nächste auftretende $\rm H$–Symbol wird als $-1$ (Minus) dargestellt, weil das letzte $\rm H$–Symbol als $+1$ (Plus) codiert wurde.
- Auch beim Zustand $\rm O$ wird das aktuelle Binärsymbol $\rm L$ mit dem Ternärwert $0$§ dargestellt. Im Unterschied zum Zustand $\rm N$ wird aber nun das nächste auftretende $\rm H$–Symbol als $+1$ (Plus) dargestellt werden, da das letzte $\rm H$–Symbol als $-1$ (Minus) codiert wurde.
$\text{Fazit:}$
- Die $\rm MQ4$–Ausgangsfolge entspricht tatsächlich den Regeln des AMI–Codes und weist die Entropie $H = 1.000 \hspace{0.05cm} \rm bit/Symbol$ auf.
- Aufgrund des neuen Zustandes $\rm O$ ist nun allerdings $H_0 = 2.000 \hspace{0.05cm} \rm bit/Symbol$ (gegenüber $1.585 \hspace{0.05cm} \rm bit/Symbol$) deutlich zu groß.
- Auch alle $H_k$–Näherungen sind größer als beim AMI–Code.
- Erst für $k \to \infty$ stimmen $\rm MQ4$ und AMI-Code überein: $H = 1.000 \hspace{0.05cm} \rm bit/Symbol$.
Aufgaben zum Kapitel
Aufgabe 1.3: Entropienäherungen
Aufgabe 1.4: Entropienäherungen für den AMI-Code
Zusatzaufgabe 1.4Z: Entropie der AMI-Codierung
Aufgabe 1.5: Binäre Markovquelle
Aufgabe 1.5Z: Symmetrische Markovquelle
Aufgabe 1.6: Nichtbinäre Markovquellen
Aufgabe 1.6Z:Ternäre Markovquelle